简介
bbolt是一个golang实现的 B+树持久KV,被etcd用作存储后端。bbolt支持多读单写事务模型以及嵌套的B+树实现,具有良好的顺序读取性能。
代码量不大,一共18495行Go代码,去掉测试和命令行后的核心代码只有6511行,架构设计优秀,模块实现简单清晰,适合学习。
阅读代码时按照自底向上的顺序开始,从最底层的页面管理、磁盘布局到内存节点、逻辑B+树实现再到事务和数据库实现。
整体架构如下图所示
B+树
在剖析bbolt代码之前,先来简单讨论一下B+树。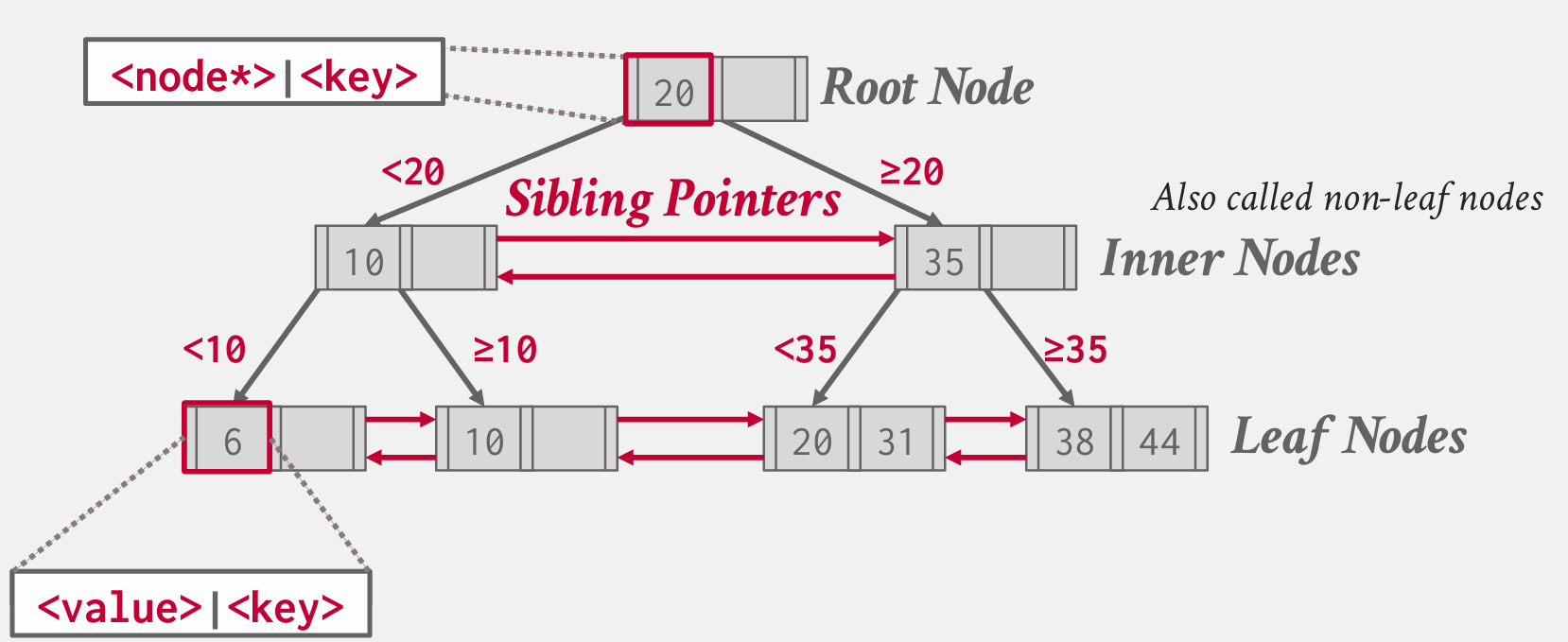
B+ 树具有如下属性:
- 根节点和中间节点指向下一级节点,存储
(key,page_id/node*) - 最底层的叶子节点存储实际的KV
- 相邻的兄弟节点间维护
prev & next指针用于顺序遍历 - 中间节点使用
K个元素索引下一级的K+1个元素。- 如图所示,非叶子节点的第K个元素用于索引$child_{k}(all(key<Key_{k}))和child_{k+1}(all(key\geq Key_{k}))$
- 节点的大小超过PageSize后会进行拆分,节点删除元素后如果大小小于阈值会和兄弟节点进行合并,或者从兄弟节点“借数据”。
B+树的优缺点非常明显:
- 优点:
- 中间节点不存实际数据,只存索引,树的高度较低,查询时间稳定;磁盘IO少
- 范围查询性能高
- 中间节点可以完全缓存
- 缺点:
- 随机写性能不佳,点读性能一般
- 并发控制复杂(涉及到树节点的分裂、合并,如果是节点级别的并发控制,由于节点同时被父节点和兄弟节点持有,实现更加棘手)
bbolt面向的场景是需要磁盘持久化+多读少写,事务语义是多读单写,因此选用B+树是一个合理的设计。
为了简化并发控制和B+树实现,bbolt选择略微牺牲顺序遍历性能,取消兄弟指针,没有实现典型B+树。因此兄弟节点间的移动需要通过祖先节点进行。
同时中间节点使用K个元素索引下一级的K个元素,是1:1的对应关系。中间节点的第K项对应第K个子节点的FirstKey
布局总览
磁盘布局和内存结构整体设计如图
- 单个bbolt数据库对应一个磁盘上的文件,在启动时通过
mmap(PROT_READ,MAP_SHARED)映射用户空间并使用;- 将
BufferPool的职责转移给mmap,可能会带来系统颠簸(内存页换出,读取); 可以使用mlock来固定住需要使用的内存1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// mmap memory maps a DB's data file.
func mmap(db *DB, sz int) error {
// Map the data file to memory.
b, err := unix.Mmap(int(db.file.Fd()), 0, sz, syscall.PROT_READ, syscall.MAP_SHARED|db.MmapFlags)
if err != nil {
return err
}
// Advise the kernel that the mmap is accessed randomly.
err = unix.Madvise(b, syscall.MADV_RANDOM)
if err != nil && err != syscall.ENOSYS {
// Ignore not implemented error in kernel because it still works.
return fmt.Errorf("madvise: %s", err)
}
// Save the original byte slice and convert to a byte array pointer.
db.dataref = b
db.data = (*[common.MaxMapSize]byte)(unsafe.Pointer(&b[0]))
db.datasz = sz
return nil
}
- 将
- 内存和磁盘页采用分页管理,使用
pgid来索引; 访问对应的Page其实就是将给定偏移量处的内存地址类型转换为Page*1
2
3
4
5
6
7
8
9
10// page retrieves a page reference from the mmap based on the current page size.
func (db *DB) page(id common.Pgid) *common.Page {
pos := id * common.Pgid(db.pageSize)
return (*common.Page)(unsafe.Pointer(&db.data[pos]))
}
// pageInBuffer retrieves a page reference from a given byte array based on the current page size.
func (db *DB) pageInBuffer(b []byte, id common.Pgid) *common.Page {
return (*common.Page)(unsafe.Pointer(&b[id*common.Pgid(db.pageSize)]))
} - 磁盘页对应的节点在内存中反序列化为Node结构体,写事务在内存更改
Node后,可能会拆分并写入到内存Page(Golang Heap管理),在序列化到磁盘后可以通过mmap的内存访问1
2
3
4
5
6
7
8
9
10
11
12
13// allocate returns a contiguous block of memory starting at a given page.
func (db *DB) allocate(txid common.Txid, count int) (*common.Page, error) {
// Allocate a temporary buffer for the page.
var buf []byte
if count == 1 {
buf = db.pagePool.Get().([]byte)
} else {
buf = make([]byte, count*db.pageSize)
}
p := (*common.Page)(unsafe.Pointer(&buf[0]))
p.SetOverflow(uint32(count - 1))
......
}
磁盘布局
Page
MetaPage、FreelistPage,BranchPage、LeafPage四类
所有类型的页面共用同一个PageHeader名为Page(16B)
1 | type Page struct { |
flags可以是BranchPageFlag,LeafPageFlag,MetaPageFlag,FreelistPageFlag其中之一overflow: 当KV超过4KB时需要拆分到多个连续的页面Pages,Pages的第一个页面使用overflow记录后面还有多少连续页面bbolt并没有具体的LeafPage & BranchPage & MetaPage结构体, 而是根据标志位来决定调用哪些函数来访问数据
MetaPage
bbolt交替写入两个metapage来实现崩溃恢复, metapage固定占据文件的前两个页,在创建时写入或这事务提交时写入,记录整个系统必须的元数据(pagesize,根目录在哪个页面,freelist从哪个页面开始等); 使用txid % 2 决定写入哪个MetaPage,崩溃时使用最新(txid最大)的页面进行恢复。
1 | type Meta struct { |
FreelistPage
没什么好说的,记录连续的pgid,崩溃后读取并加载,可以直接用于分配
LeafPage & BranchPage
leafpage紧凑存放element和KV,好处是连续遍历,二分查找
1 | ┌────────────────┬─────────────────────────────┬────────────────────────┐ |
leafPageElement需要使用flags来区分存放的是普通KV还是一个嵌套的Bucket,我们留到后续再来讨论
1 | type leafPageElement struct { |
获取leafPage的Elems只需要根据 count和ElemSize计算到对应的偏移量即可
1 | // LeafPageElement retrieves the leaf node by index |
根据Elem获取KV也是同理
1 | // Key returns a byte slice of the node key. |
页面内部的查找连续遍历数据即可
1 | // If we have a page then search its leaf elements. |
同理BranchPage也是紧凑布局,唯一不同的是BranchPage在Elem中存放Value(子页面的Pgid), 尾部只存放连续的Key
1 | ┌────────────────┬─────────────────────────────┬────────────────┐ |
Bucket
bbolt里bucket表示一棵B+树,对应一个命名空间。多个B+树之间可以互相独立,也可以存在嵌套关系。bbolt api 要求读取KV前必须定位到某个特定的Bucket。Bucket有固定的Header表示, root指向B+树的根页面。
1 | // InBucket represents the on-file representation of a bucket. |
bbolt在初始化时会创建一个匿名的根Bucket,用户在该Bucket下创建具名的B+树。所有的外部操作都是从这个匿名的根开始的。
1 | Meta 页 |
Bucket只会存在于叶子节点,Key就是Bucket的名字,Value根据磁盘布局会发生改变。如果某个Bucket没有嵌套的子Bucket或者Size< PageSize/4,那么采用内联布局节省空间。root==0表示采用内联布局,BucketHeader后紧跟PageData(叶子页面数据序列化到Page后的格式)
1 | +------------------------------------------------------------------+ |
否则采用普通布局, root!=0,指向具体的B+树根页面
1 | +------------------+------------------+ |
事务
bbolt设计中,事务Tx对外提供读写接口,Bucket定位到具体的B+树执行操作,Cursor结构提供B+树的逻辑视图,用于迭代/操作B+树。
调用链是 DB -> Tx -> Bucket -> Cursor -> Node, 上级为下级提供资源访问接口,下级为上级提供逻辑视图与实际操作的封装。
标准的使用方式如下:
View接口提供出错自动回滚的只读事务,Update接口提供自动回滚或提交的读写事务,Batch接口用于批量处理事务。- 通过
Tx增删改查某个Bucket; - 获取到
Bucket后单点插入或删除; - 通过
Bucket.Cursor遍历B+树并执行操作。 Bucket & Cursor是B+树的逻辑视图,生命周期跟创建它们的事务绑定当然也可以手动管理事务:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15db.View(func(tx *bolt.Tx) error {
// Assume bucket exists and has keys
b := tx.Bucket([]byte("MyBucket"))
c := b.Cursor()
for k, v := c.First(); k != nil; k, v = c.Next() {
fmt.Printf("key=%s, value=%s\n", k, v)
}
return nil
})
db.Update(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte("MyBucket"))
err := b.Put([]byte("answer"), []byte("42"))
return err
})按照调用链的反方向来剖析这些结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Start a writable transaction.
tx, err := db.Begin(true)
if err != nil {
return err
}
defer tx.Rollback()
// Use the transaction...
_, err := tx.CreateBucket([]byte("MyBucket"))
if err != nil {
return err
}
// Commit the transaction and check for error.
if err := tx.Commit(); err != nil {
return err
}
Node
写事务进行具体操作时不能直接修改磁盘上的页面,而是要将其物化成内存表示,修改后统一提交。Node就是磁盘页面(一个或多个)在内存的表示,Inode则是紧凑的Elem + KV内存表示
1 | // node represents an in-memory, deserialized page. |
Node通过parent的childAt(index)和childIndex(node*)实现兄弟节点间的移动。Node实现了拆分,合并逻辑。B+树级别的拆分合并其实就是节点自下而上的递归拆分合并。
节点拆分就是 split(pagesize) -> splitTwo(pagesize) -> splitIndex(threshold)的连续调用;
split记录[]node,持续对拆分后的右节点调用splitTwo直到无法拆分splitTwo- 如果
len(node.inodes) <= 4 || node.size() < PageSize那么不进行拆分;否则根据FillPercent(默认0.5) 来计算拆分阈值, 根据splitIndex计算出的结果来迁移node.inodes[index:]到新的节点 - 记录新节点到
node.parent,如果不存在parent则创建
- 如果
splitIndex: 至少给右节点留两个inode,再次基础上,如果有累计大小超过阈值的Index,直接返回
整体的拆分逻辑则集成在spill函数,实现细节还是很多,一点点来看:- 自下而上递归调用
spill,到叶子节点后才开始执行操作,所有子节点操作执行完后再进行本节点操作 - 拆分本节点,释放节点对应的旧页面空间
- 为节点分配新的连续页面(节点至少要有2个KV,如果遇到超大KV,即使只有1个也会对应多个页面)
- 在
parent中创建节点对应的Elem - 处理根节点分裂的特殊情况合并的逻辑类似:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69// spill writes the nodes to dirty pages and splits nodes as it goes.
// Returns an error if dirty pages cannot be allocated.
func (n *node) spill() error {
var tx = n.bucket.tx
if n.spilled {
return nil
}
// Spill child nodes first. Child nodes can materialize sibling nodes in
// the case of split-merge so we cannot use a range loop. We have to check
// the children size on every loop iteration.
sort.Sort(n.children)
for i := 0; i < len(n.children); i++ {
if err := n.children[i].spill(); err != nil {
return err
}
}
// We no longer need the child list because it's only used for spill tracking.
n.children = nil
// Split nodes into appropriate sizes. The first node will always be n.
var nodes = n.split(uintptr(tx.db.pageSize))
for _, node := range nodes {
// Add node's page to the freelist if it's not new.
if node.pgid > 0 {
tx.db.freelist.Free(tx.meta.Txid(), tx.page(node.pgid))
node.pgid = 0
}
// Allocate contiguous space for the node.
p, err := tx.allocate((node.size() + tx.db.pageSize - 1) / tx.db.pageSize)
if err != nil {
return err
}
// Write the node.
if p.Id() >= tx.meta.Pgid() {
panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", p.Id(), tx.meta.Pgid()))
}
node.pgid = p.Id()
node.write(p)
node.spilled = true
// Insert into parent inodes.
if node.parent != nil {
var key = node.key
if key == nil {
key = node.inodes[0].Key()
}
node.parent.put(key, node.inodes[0].Key(), nil, node.pgid, 0)
node.key = node.inodes[0].Key()
common.Assert(len(node.key) > 0, "spill: zero-length node key")
}
// Update the statistics.
tx.stats.IncSpill(1)
}
// If the root node split and created a new root then we need to spill that
// as well. We'll clear out the children to make sure it doesn't try to respill.
if n.parent != nil && n.parent.pgid == 0 {
n.children = nil
return n.parent.spill()
}
return nil
}
- 特殊处理根节点,如果只有一个子项,那么直接合并子项的所有元素
- 删除空节点并释放页面
- 如果待合并节点是父节点的最左节点,那么和右兄弟合并;否则和左兄弟合并;
- 调用父节点的合并函数
Cursor
Cursor是Bucket的迭代器,能够顺序迭代Bucket中的所有KV,Cursor会区分普通KV和嵌套Bucket,由调用方进行过滤
Cursor指向待遍历的B+树,存储当前的遍历路径。合法Cursor的最后一个节点一定是叶子节点。
只有写事务才会物化Page,如果是读事务,当前Bucket不存在Node结构,通过引用内存中的Page也可以完成访问,减少序列化带来的开销。
1 | type Cursor struct { |
Cursor的First&Last&Prev&Next函数就是树的遍历,此处略过。Cursor提供Seek(key)来移动到第一个大于等于Key的位置,具体流程如下:
- 从根节点开始遍历所有的中间节点,找到$index_{curKey\geq targetKey}$ ,随后判断当前位置的Key是否和目标Key严格相等,不等则index–; (回顾上文提到的bbolt B+Tree模型, 中间节点的K项指向第K个子节点,记录子节点的FirstKey)
- 到叶子节点后找到$index_{curKey\geq targetKey}$ ,然后设置
stack.last().index随后返回
由于Node,Page都是有序紧凑连续存储,使用sort.Search二分查找, 该函数返回使条件成真的最小Index或者数组长度来表示不存在1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45// 中间页面的查找
func (c *Cursor) searchPage(key []byte, p *common.Page) {
// Binary search for the correct range.
inodes := p.BranchPageElements()
var exact bool
index := sort.Search(int(p.Count()), func(i int) bool {
// TODO(benbjohnson): Optimize this range search. It's a bit hacky right now.
// sort.Search() finds the lowest index where f() != -1 but we need the highest index.
ret := bytes.Compare(inodes[i].Key(), key)
if ret == 0 {
exact = true
}
return ret != -1
})
if !exact && index > 0 {
index--
}
c.stack[len(c.stack)-1].index = index
// Recursively search to the next page.
c.search(key, inodes[index].Pgid())
}
// 叶子节点的查找,找到第一个>=key的index
func (c *Cursor) nsearch(key []byte) {
e := &c.stack[len(c.stack)-1]
p, n := e.page, e.node
// If we have a node then search its inodes.
if n != nil {
index := sort.Search(len(n.inodes), func(i int) bool {
return bytes.Compare(n.inodes[i].Key(), key) != -1
})
e.index = index
return
}
// If we have a page then search its leaf elements.
inodes := p.LeafPageElements()
index := sort.Search(int(p.Count()), func(i int) bool {
return bytes.Compare(inodes[i].Key(), key) != -1
})
e.index = index
}
Bucket
Node提供了基本的节点操作,Cursor提供了树的遍历, Bucket只需要保存物化的节点,缓存数据,对外提供树接口。
1 | // Bucket represents a collection of key/value pairs inside the database. |
Bucket创建Cursor,定位到对应Key,然后获取node执行操作
1 | // Move cursor to correct position. |
Tx
DB是对外暴露的核心接口,负责数据库生命周期、事务调度、Bucket CRUD、锁协调、批量写合并和空间压缩。
实际读写操作在Tx中进行,Tx将KV操作委托给Bucket,事务层管理只读和读写事务的生命周期,通过COW保证快照隔离,提供 Commit/Rollback 语义。
bbolt主动维护磁盘页面的分配和写入缓冲页面的分配:
- 写入缓冲页面用于
node在内存中拆分为多个页面,在写入磁盘前存储数据,由db.sync.Pool维护,调用node.write(Page)前分配,写入Page到磁盘后回收 - 磁盘页面的分配回收由
freelist结构体维护,写事务提交时申请页面写入,读事务开始时加入freelist,固定住待读取的页面。- 申请页面的事务和释放页面的事务一定不相同。因为在数据库初始化后,所有新分配的页面都由写事务申请,在写事务提交后成为最新的干净页面。这些页面始终有效直到被新的写事务
COW修改,并且释放。
- 申请页面的事务和释放页面的事务一定不相同。因为在数据库初始化后,所有新分配的页面都由写事务申请,在写事务提交后成为最新的干净页面。这些页面始终有效直到被新的写事务
- 写事务提交时根据水位线决定数据库是否扩容
freelist
freelist有array和hashmap两种实现,两种实现的不同只是页面记录、合并方式不同,核心逻辑是一致的,实现在Interface接口:
Allocate为某个事务分配连续的N个页面,mergeSpans回收连续的N个页面AddReadonlyTXID(txid common.Txid)&RemoveReadonlyTXID(txid common.Txid): 记录读事务生命周期ReleasePendingPages(): 写事务开始前释放未被读事务引用的旧页面Free(txId common.Txid, p *common.Page)将页面加入待释放列表Rollback(txId common.Txid)回滚未提交的事务所有的更改1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20type Interface interface {
ReadWriter
// Allocate tries to allocate the given number of contiguous pages
// from the free list pages. It returns the starting page ID if
// available; otherwise, it returns 0.
Allocate(txid common.Txid, numPages int) common.Pgid
// AddReadonlyTXID adds a given read-only transaction id for pending page tracking.
AddReadonlyTXID(txid common.Txid)
// RemoveReadonlyTXID removes a given read-only transaction id for pending page tracking.
RemoveReadonlyTXID(txid common.Txid)
// ReleasePendingPages releases any pages associated with closed read-only transactions.
ReleasePendingPages()
// Free releases a page and its overflow for a given transaction id.
// If the page is already free or is one of the meta pages, then a panic will occur.
Free(txId common.Txid, p *common.Page)
// Rollback removes the pages from a given pending tx.
Rollback(txId common.Txid)
// mergeSpans is merging the given pages into the freelist
mergeSpans(ids common.Pgids)
}shared结构体实现Interface的绝大部分接口,Allocate & mergeSpans交给具体的freelistarrayFreelist是一个连续的页面数组,Allocate就是查找连续的N个页面,然后返回起始页面;mergeSpan则是找到待回收页面的插入位置,然后插入连续的N个页面1
2
3
4type array struct {
*shared
ids []common.Pgid // all free and available free page ids.
}shared实现如下:txPending记录写事务要释放的页面列表,以及这些页面的分配时间(Txid),只有小于当前最小活跃读事务的页面才可以被回收;lastReleaseBegin记录最近尝试释放txPending的事务,防止多次无效扫描allocs记录所有页面的分配时间戳cache用于快速查找某个页面是否存在1
2
3
4
5
6
7
8
9
10
11
12
13
14type txPending struct {
ids []common.Pgid
alloctx []common.Txid // txids allocating the ids
lastReleaseBegin common.Txid // beginning txid of last matching releaseRange
}
type shared struct {
Interface
readonlyTXIDs []common.Txid // all readonly transaction IDs.
allocs map[common.Pgid]common.Txid // mapping of Txid that allocated a pgid. Allocate时修改,Pgid是连续分配的第一个页面
cache map[common.Pgid]struct{} // fast lookup of all free and pending page ids.
pending map[common.Txid]*txPending // mapping of soon-to-be free page ids by tx.
}Free在同一个写事务内部可能被多次调用,节点分裂会触发旧节点页面的释放,节点合并会触发待合并节点页面的释放:
- 第一次释放时创建
txPending并追踪 - 从
shared.alloc中移除待释放的页面 - 记录待释放的页面到
txPending并加入cache1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32func (t *shared) Free(txid common.Txid, p *common.Page) {
if p.Id() <= 1 {
panic(fmt.Sprintf("cannot free page 0 or 1: %d", p.Id()))
}
// Free page and all its overflow pages.
txp := t.pending[txid]
if txp == nil {
txp = &txPending{}
t.pending[txid] = txp
}
allocTxid, ok := t.allocs[p.Id()]
common.Verify(func() {
if allocTxid == txid {
panic(fmt.Sprintf("free: freed page (%d) was allocated by the same transaction (%d)", p.Id(), txid))
}
})
if ok {
delete(t.allocs, p.Id())
}
for id := p.Id(); id <= p.Id()+common.Pgid(p.Overflow()); id++ {
// Verify that page is not already free.
if _, ok := t.cache[id]; ok {
panic(fmt.Sprintf("page %d already freed", id))
}
// Add to the freelist and cache.
txp.ids = append(txp.ids, id)
txp.alloctx = append(txp.alloctx, allocTxid)
t.cache[id] = struct{}{}
}
}Rollback就是Free的反向操作: - 从cache中删除pending页面
- 将shared.alloctx中的pgid和allocTxid还原到allocs中
- 从pending中删除txid
- 从allocs中删除txid分配的pgid
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30func (t *shared) Rollback(txid common.Txid) {
// Remove page ids from cache.
txp := t.pending[txid]
if txp == nil {
return
}
for i, pgid := range txp.ids {
delete(t.cache, pgid)
tx := txp.alloctx[i]
if tx == 0 {
continue
}
if tx != txid {
// Pending free aborted; restore page back to alloc list.
t.allocs[pgid] = tx
} else {
// A writing TXN should never free a page which was allocated by itself.
panic(fmt.Sprintf("rollback: freed page (%d) was allocated by the same transaction (%d)", pgid, txid))
}
}
// Remove pages from pending list and mark as free if allocated by txid.
delete(t.pending, txid)
// Remove pgids which are allocated by this txid
for pgid, tid := range t.allocs {
if tid == txid {
delete(t.allocs, pgid)
}
}
}ReleasePendingPages: 释放掉所有小于最早的只读事务的pending页面,以及所有在只读事务范围间隙的pending页面1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 释放掉所有小于最早的只读事务的pending页面,以及所有在只读事务范围间隙的pending页面
func (t *shared) ReleasePendingPages() {
// Free all pending pages prior to the earliest open transaction.
sort.Sort(txIDx(t.readonlyTXIDs))
minid := common.Txid(math.MaxUint64)
if len(t.readonlyTXIDs) > 0 {
minid = t.readonlyTXIDs[0]
}
if minid > 0 {
t.release(minid - 1)
}
// Release unused txid extents.
for _, tid := range t.readonlyTXIDs {
t.releaseRange(minid, tid-1)
minid = tid + 1
}
t.releaseRange(minid, common.Txid(math.MaxUint64))
// Any page both allocated and freed in an extent is safe to release.
}
TX
读事务通过func (db *DB) beginTx() (*Tx, error)创建,创建时需要先持有metalock然后再持有mmap.RLock(),初始化完毕后释放metalock(),继续持有mmap.RLock确保读事务进行时不会发生remmap
写事务通过func (db *DB) beginRWTx() (*Tx, error)创建,创建时先持有rwlock然后再持有metalock, 初始化完毕后会注册自身到db,db运行时只会有唯一的RWTx,同样释放metalock,继续持有rwlock阻塞其他写事务的创建
读事务执行完毕后默认RollBack1,在close时释放锁和资源
写事务执行完毕后默认Commit:
- 进行树的合并、拆分并且设置
meta.RootBucket(绝大部分情况不会修改,懒得判断是否产生新根,一次set操作保平安) - 释放掉
old freelist page,创建新的freelistpage(存储到golang heap),依旧没有落盘 - 判断分配的逻辑页面是否超过实际文件大小,是则扩容
- 数据落盘,然后根据
txid % 2的结果,落盘元数据 - 关闭事务,释放资源和锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47func (tx *Tx) Commit() (err error) {
txId := tx.ID()
// Rebalance nodes which have had deletions.
tx.root.rebalance()
opgid := tx.meta.Pgid()
// spill data onto dirty pages.
if err = tx.root.spill(); err != nil {
tx.rollback()
return err
}
// Free the old root bucket.
tx.meta.RootBucket().SetRootPage(tx.root.RootPage())
// Free the old freelist because commit writes out a fresh freelist.
if tx.meta.Freelist() != common.PgidNoFreelist {
tx.db.freelist.Free(tx.meta.Txid(), tx.db.page(tx.meta.Freelist()))
}
err = tx.commitFreelist()
if err != nil {
lg.Errorf("committing freelist failed: %v", err)
return err
}
// If the high water mark has moved up then attempt to grow the database.
if tx.meta.Pgid() > opgid {
if err = tx.db.grow(int(tx.meta.Pgid()+1) * tx.db.pageSize); err != nil {
tx.rollback()
return err
}
}
// Write dirty pages to disk.
if err = tx.write(); err != nil {
tx.rollback()
return err
}
// Write meta to disk.
if err = tx.writeMeta(); err != nil {
tx.rollback()
return err
}
// Finalize the transaction.
tx.close()
// Execute commit handlers now that the locks have been removed.
for _, fn := range tx.commitHandlers {
fn()
}
return nil
}
小结
bbolt功能完整,模块清晰,是一个优秀的磁盘B+树KV,值得学习。但是在K8S+云场景下,磁盘架构以及通用存储的设计理念导致bbolt成为存储瓶颈,需要针对内存架构重新设计