本文是阅读Distributed System for fun and profit和DDIA 2时,阅读部分补充文献并对概念进行拓展和延伸后的笔记。权当抛砖引玉,若有错漏,欢迎指正。
感谢两本书的作者,带我们领略分布式领域的奥妙。
感谢Claude,耐心专业严谨地解答了我阅读时的困惑
序
分布式系统的一切问题都源于空间与时间
分布式系统通过多个节点协作来完成某项任务,节点之间通过消息通信传播来同步,从而分步骤/分模块地推进任务。
然而信息最快以光速传播,而节点处理信息的速度(op/ns)远快于信息传播的速度(op/ms),并且每个节点对于物理时间的观测是不一致的,无法观测到全局一致的物理时间,因此找到一种方式观测到确定的事件发生顺序是分布式系统的首要任务。
计算机学家Lamport对此提出深刻洞察: 分布式系统中,时间不是绝对刻度,事件之间可被观测的因果结构才是。
举例说明:
- 微信用户A在上午10:00发了条朋友圈吐槽导师
- 微信用户B在上午10:00:30看到了这条朋友圈,于是回复: “忍耐!”
- 微信用户C在上午10:00也发了条朋友圈,感叹终于毕业了
在现实世界中,A的发生先于B,事件A,B是有因果关系的,这种关系在分布式中被定义为happened before,即A happened Before B。系统需要正确观测到事件A和B的顺序。
但是C和事件A,B没有这种关系,因此称事件C和事件A,事件B是并发的。并发指的是无法确认顺序,或者说彼此之间的顺序没有意义。
此处的并发和因果是从分布式系统角度定义的,微信服务器不考虑A和C是不是同门,他们是否约定好在某个时间一起发朋友圈。
如果存在这种情况,那么事件A和C存在外部的因果,系统无法识别和观测,也没有意义。
显然不加限制地使用物理时间作为刻度会无法确保正确观测到happened before关系。假设两台服务器A和B通信,但是A的时间快了50ms,B快了20ms, A在本地时间10:00发送消息,B在本地时间9:59.980处理了消息。两台服务器将事件处理+本地物理时间戳推送到审计服务器,审计服务器就会观测到事件B发生在事件A之前。
或者参考DDIA的图: B的写入在因果上晚于A,但是具有更小的物理时间戳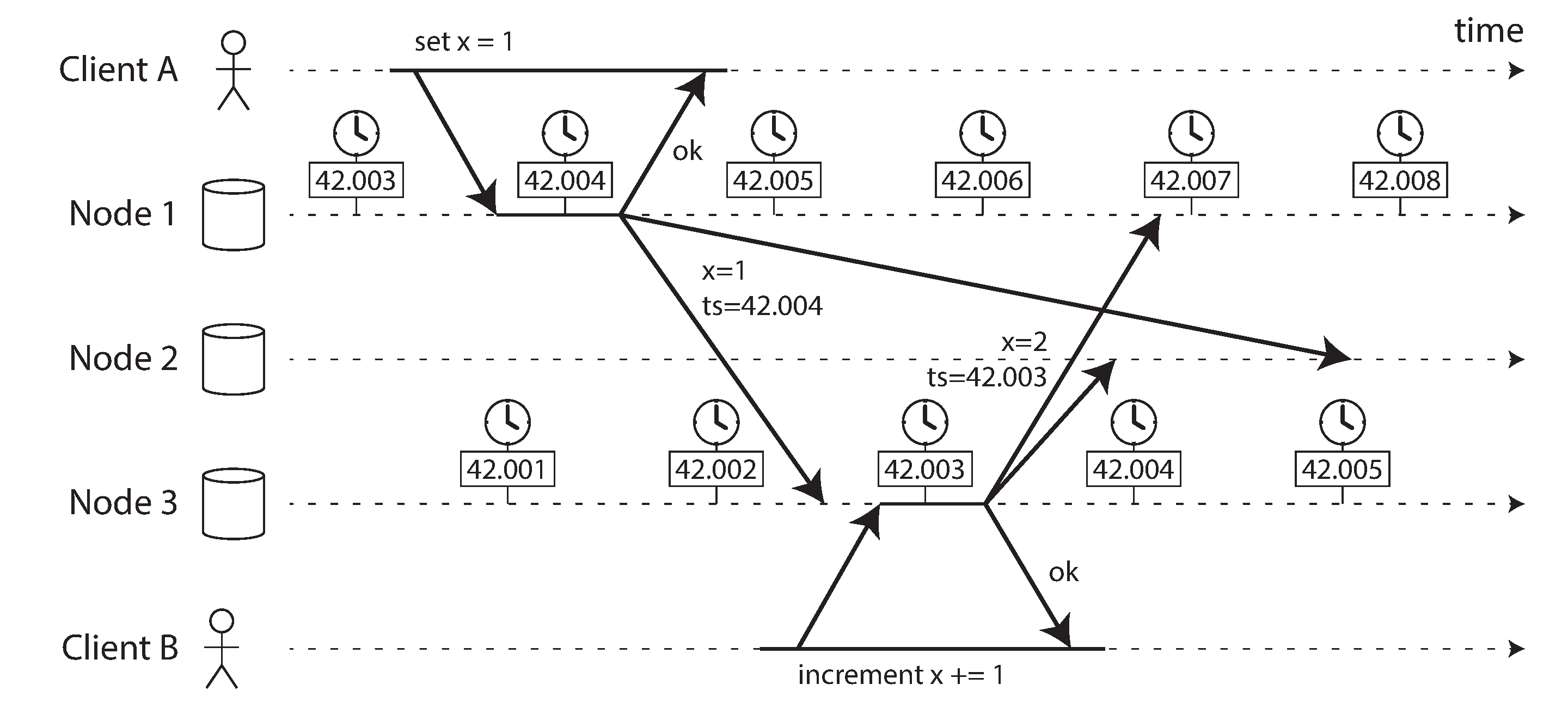
Lamport逻辑时钟是探讨分布式领域时间与顺序的开山之作,他指出在分布式系统中,有时根本无法判断两个事件究竟哪一个先发生。消息传输延迟与单进程内事件间隔相比不可忽略,不同进程各自拥有独立的执行历史。如果我们仍然强行要求一个全局的、物理意义上的“先/后”判断,就必须依赖同步的物理时钟;而物理时钟本身既不精确,也会漂移。因此,他主张完全从系统内部可观测的事件出发来定义“happened before”这一关系。与其追问“物理上谁先谁后”,不如先承认我们只能确定一种更弱的、由进程内顺序和消息传递所诱导的因果顺序;然后在此基础上,用逻辑时钟把它扩展成一个对分布式实现有用的全序。
但依旧存在某些情况,系统会受到外部性的影响,此时需要使用一个系统外部、所有进程共享的参照系,即物理时间。使用物理时间需要多个观察者迫近绝对时间,对观察者之间的时间偏差/时间精度有一定要求,Lamport给出了修正公式。只要物理时钟的偏差在一定的阈值内,就可以使用。
时钟分类图如下所示:我们将按照逻辑时钟、物理时钟、混合时钟的顺序来逐一探索。
flowchart TD
A[分布式系统中的时钟] --> B[逻辑时钟]
A --> C[物理时钟]
A --> E[混合方案]
B --> B1[Lamport 时钟]
B --> B2[向量时钟]
C --> C1[Lamport 时钟]
C --> C2[TrueTime]
E --> E1[HLC]
逻辑时钟
Lamport时钟
系统建模
Lamport将系统建模为若干进程和消息通信,每一个进程是一串事件的无穷序列或者有穷序列,同一进程内的事件具有全序(所有事件之间可以排序),进程之间发送消息和接收消息被视为事件。进程之间的事件关系由消息通信触发。
sequenceDiagram
participant P as Process P
participant Q as Process Q
Note over P: event p1
P->>Q: message m1
Note over Q: event q1
Note over P: event p2
Note over Q: event q2
Q->>P: message m2
Note over P: event p3
通过空间时间图可以直观地看出happened before关系,横轴表示空间(进程),纵轴表示时间(时间轴从上至下延展)。如果两个事件之间可以通过箭头连接(可以到达),那么两个事件可以建立happened before关系,否则,两个事件是并发的。
从上述图中可以看出如下的happened before关系:
p1 -> q1 -> q2 -> p3p1 -> p2 -> p3
p2 和q1,q2是并发的,他们之间不可以排序。
Happened before
Happened before是事件集合上的偏序关系,具有如下性质:
- 进程内顺序: 若 $a, b$ 是同一进程的两个事件,且 $a$ 在 $b$ 之前发生,则 $a \rightarrow b$。
- 消息传递: 若 $a$ 是某进程发送消息 $m$ 的事件,$b$ 是另一进程接收同一消息 $m$ 的事件,则 $a \rightarrow b$。
- 传递闭包: 若 $a \rightarrow b$ 且 $b \rightarrow c$,则 $a \rightarrow c$。
形式化写作: $a \rightarrow b ;\Longleftrightarrow; \text{(同进程先后)} \lor \text{(send/receive 同一消息)} \lor \exists c: a \rightarrow c \land c \rightarrow b.$
不满足上述关系的事件被称为并发。重要的事情说三遍,再来赘述一遍:此处的并发并不意味着物理时间上同时发生,而仅表示二者之间不存在可通过系统内部消息传递链建立的因果影响关系。以下是Lamport老爷子论文原文。
This definition will appear quite natural to the reader familiar with the invariant space-time formulation of special relativity… we have taken the more pragmatic approach of only considering messages that actually are sent.
很遗憾,Lamport老爷子没给出一个判断happened before关系的工具,论文中的Lamport Logical Clock只是一种从偏序构造全序的方式。如果想要判断happened before,得使用其他方式。但是该论文的留白与不足成全后面四十年的探索。如果他一个人干完了,学术界就没饭吃了。
从偏序到全序
直观了解和形式定义Happened before关系之后,还需要一种工具对事件进行排序,并且这种排序不违背事件发生的因果关系,这就是Lamport Logical Clock。
事件发生时需要携带逻辑时钟,通过逻辑时钟的可比性来确定事件之间的偏序关系。显然可得$\text{Clock Condition:}\quad \text{若 } a \rightarrow b, \text{ 则 } C(a) < C(b).$成立。
按照建模,将其拆分为更具体的两个条件:
- C1:若 $a, b$ 是同一进程 $P_i$ 内的事件,且 $a$ 在 $b$ 之前,则 $C_i(a) < C_i(b)$。
- C2:若 $a$ 是 $P_i$ 发送消息 $m$ 的事件,$b$ 是 $P_j$ 接收该消息的事件,则 $C_i(a) < C_j(b)$。
基于上述条件,论文中给出了两条实现规则,无需物理时钟就可实现,逻辑时钟通常就是一个计数器: - IR1:进程 $P_i$ 在任意两个连续事件之间递增自己的时钟 $C_i$。
- **IR2(a)**:当 $P_i$ 发送消息 $m$ 时,消息携带时间戳 $T_m = C_i(\text{send event})$。
- **IR2(b)**:当 $P_j$ 收到消息 $m$ 时,将 $C_j$ 设置为不小于当前值且大于 $T_m$ 的值。
代码实现简单直观:
1 | impl LamportClock { |
时钟条件的逆命题不成立,即$C(a)< A(b) \to a\to b$不成立。
逻辑时钟只能保证部分序:它不违背事件的因果顺序,但无法区分并发事件和因果关系。而且许多分布式同步问题需要一个确定性的全序。Lamport 的做法是:先用逻辑时钟给出数值顺序,再用进程间的一个任意全序 $\prec$ 来打破平局。
定义全序关系 $\Rightarrow$ 如下:设 $a$ 是进程 $P_i$ 的事件,$b$ 是进程 $P_j$ 的事件,则$a \Rightarrow b ;\Longleftrightarrow; C_i(a) < C_j(b) ;\lor; \big(C_i(a) = C_j(b) ;\land; P_i \prec P_j\big).$
这里 $P_i \prec P_j$ 可以是任意预先约定的进程顺序(如进程 ID 大小)。
原文还提到,若希望更公平,可以把平局打破规则设计为时钟值的函数,例如 $j < C_i(a) \bmod N \le i$ 等形式,但核心思想不变:通过组合 $(\text{逻辑时间}, \text{进程标识})$,我们得到一个与 $\rightarrow$ 一致的全序。
这种全序给的太随意了,只是所有全序的可能排列中的一种,因此无法严格表示物理上的发生顺序。
只能说如果系统只想要一个顺序,那可以拿来用。
还有一个问题,每个进程必须等到有足够的信息之后,才能推进下一步,例如进程A没有完全接收到其他进程的广播,那么此时它的排序队列中事件不是最终的顺序,基于中间状态做决定是错误的。
论文用经典的单资源互斥问题来展示全序的用途。假设多个进程共享一个资源,需满足:
- I:一个进程获得资源后,必须先释放,资源才能被授予另一进程。
- II:不同进程对资源的请求必须按请求发生的顺序被授予。
- III:若每个获得资源的进程最终都释放它,则每个请求最终都会被满足。
论文指出,使用中央调度进程按“收到请求的顺序” granting 并不足够——由于网络延迟,后发生的请求可能先到达中央调度器。解决思路是:每个进程维护自己的请求队列,并用上述全序 $\Rightarrow$ 对所有请求排序。
| 规则 | 动作 | 作用 |
|---|---|---|
| 1 | $P_i$ 请求资源时,向所有进程发送带时间戳的请求消息,并将该请求放入自己的队列。 | 广播请求 |
| 2 | $P_j$ 收到 $P_i$ 的请求后,将其放入队列并回送带时间戳的确认。 | 确保发送方知道接收方已看到该请求 |
| 3 | $P_i$ 释放资源时,从队列移除自己的请求并向所有进程发送释放消息。 | 清理状态 |
| 4 | $P_j$ 收到释放消息后,从队列中移除对应请求。 | 同步清理 |
| 5 | $P_i$ 被授权资源当且仅当:(i) 其请求在队列中按 $\Rightarrow$ 排在最前;(ii) $P_i$ 已收到来自所有其他进程的、时间戳大于其请求时间戳的消息。 | 保证全局一致顺序 |
规则 5 的条件 (ii) 是关键:它保证 $P_i$ 已经知晓了所有时间戳更小的请求,因此可以放心地认为自己排在队首。原文证明该算法满足 I–III:
- I 由队列删除语义保证;
- II 由全序扩展部分序保证;
- III 由消息最终可达与规则 2、4 保证。
Lamport 进一步把这一思路抽象为状态机:所有进程独立地按相同顺序模拟执行同一组命令,从而把任意多进程同步问题归结为命令的全序执行问题。这是后续复制状态机思想的雏形。
将资源互斥转换为全序执行是本篇论文最伟大的贡献,分布式存储的并发写入可以看作资源互斥,事务的并发提交可以看作资源互斥,分布式选主是资源互斥,分布式锁也是资源互斥,一切的一切,都可以转换为确立全序。
后续的计算机学者证明了,通过全序广播和实现共识算法是等价的。也就是如果你有一个共识算法,那么它肯定需要进行全序广播;如果你能用全序广播确立全序,你就能用它实现共识算法。
如果我们需要有意义的,唯一的全序,并且需要确保高可用,共识算法就是最好的解法。
小结
Lamport逻辑时钟部分最重要地是定义Happened Before(偏序关系),以及将资源互斥转换为事件全序排序。在单机中一般就是个计数器,在分布式场景,则因为无法追踪因果,一般使用变体。
缺陷与不足:
- 无法识别并发: Lamport 时钟只能保证“若因果则数值小”,不能区分“因果先”与“并发但数值小”。这在冲突检测、版本向量等场景下不够用。
- 单计数器的信息瓶颈: 一个标量丢失了大量因果信息,导致不同进程对全局状态的理解不精确。
- 故障模型缺失: 互斥算法假设消息最终可达、按序到达、进程不死机;这些假设在真实网络(分区、拜占庭故障)中都不成立。
- 进程 ID 全序的可扩展性: 当进程动态加入或退出时,维护一个稳定的 $P_i \prec P_j$ 全序需要额外机制
贡献:
- 偏序是事实,全序是约定: 在分布式系统中,很多问题有偏序就够了。重在事件因果而非物理时间。共识算法/向量时钟 等都是在偏序的基础上构造出一种特定的全序。
向量时钟
系统建模
望文生义,向量时钟是Lamport时钟的扩展,它维护一个包含 N 个逻辑时钟的数组 [ t1, t2, ... ],向量的第i个分量就对应进程i的逻辑时钟。每个节点不是递增一个公共计数器,而是在每次内部事件时将其向量中自己的逻辑时钟递增一。因此更新规则是:
- 初始 $\mathbf{V}_i[j] = 0$ 对所有 $j$。
- 进程 $P_i$ 发生本地或发送事件时:$\mathbf{V}_i[i] \leftarrow \mathbf{V}_i[i] + 1$。
- $P_i$ 发送消息时附带当前向量;接收消息时:$\mathbf{V}_i[k] \leftarrow \max(\mathbf{V}_i[k], \mathbf{V}_m[k])$ 对所有 $k$,然后再递增 $\mathbf{V}_i[i]$。
向量时钟的比较:
- $\mathbf{V}(a) \le \mathbf{V}(b)$ 当且仅当每个分量都满足。
- $\mathbf{V}(a) < \mathbf{V}(b)$ 当且仅当 $\mathbf{V}(a) \le \mathbf{V}(b)$ 且至少一个分量严格小于。
- $a \to b$ 当且仅当 $\mathbf{V}(a) < \mathbf{V}(b)$。
- $a$ 与 $b$ 并发当且仅当 $\mathbf{V}(a) \not< \mathbf{V}(b)$ 且 $\mathbf{V}(b) \not< \mathbf{V}(a)$。
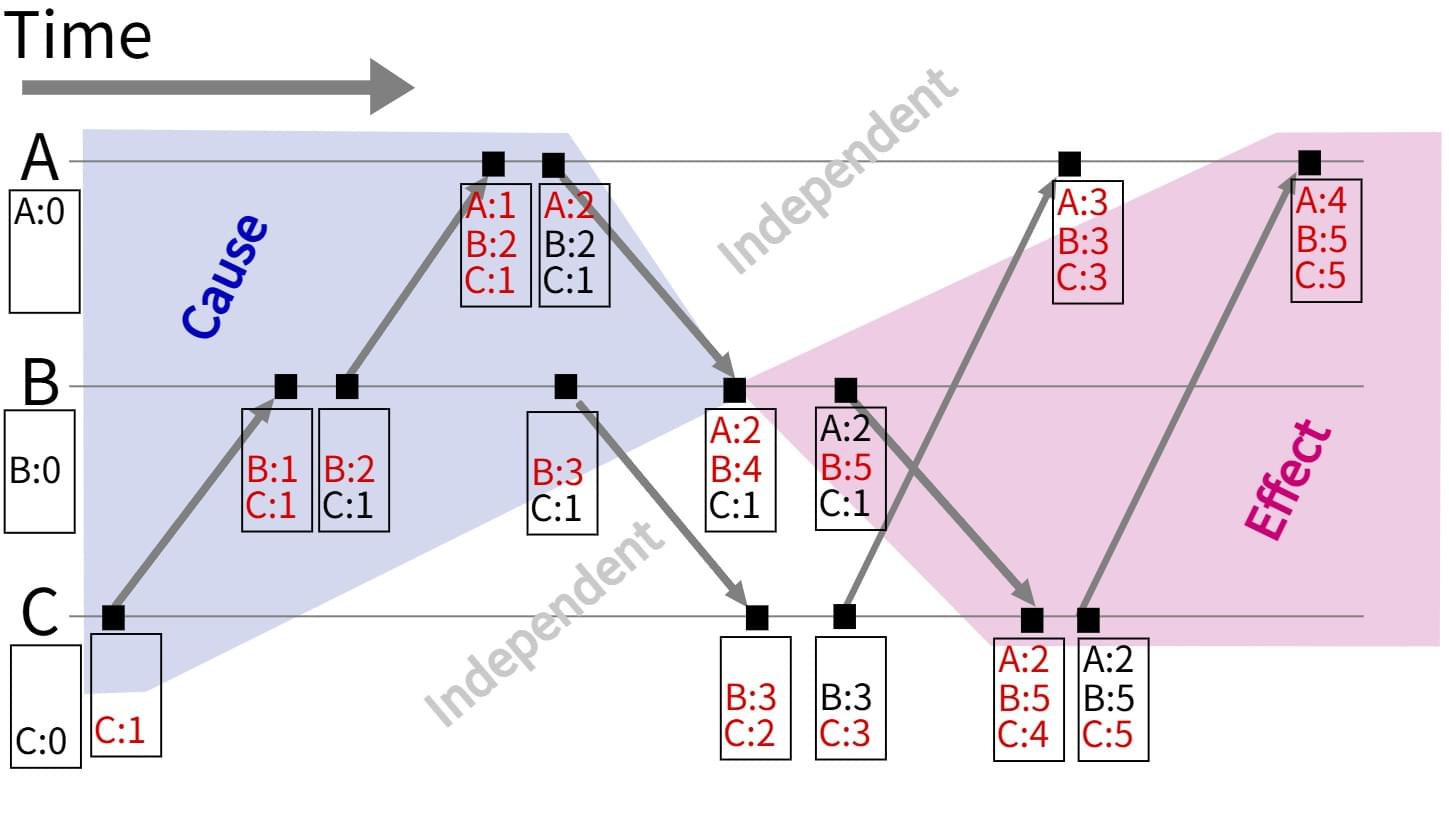
使用向量时钟可以轻松地区分并发和happened before,给出精确的因果信息,但是缺点是显然的,O(n)的时间复杂度在实际系统中往往难以接受。
向量时钟的大规模生产实践应用分为两种:
- 存储系统对象的版本管理,例如Amazon Dynamo的每个对象携带向量时钟用作版本号;向量的每一项对应一个客户端(早期版本);用于追踪因果,检测写入冲突。在这种情况下,称为
版本向量 - CRDT(无冲突复制数据类型)的因果传播: CRDT在异步网络中被许多副本共享,所有副本更新都独立发生,不依赖同步机制或回滚就能达成强最终一致性。多个副本都是可以独立更新的数据集合,副本A传播到副本B后,副本B合并A中不冲突的数据。
对于向量时钟的优化,核心就是一点:降低因果信息精确度换取更小的开销。
常见优化如下:
- 垃圾回收: 虽然向量每次都覆盖更新到最大值,但向量往往和特定对象绑定,用于MVCC管理,因此系统空间会持续膨胀。
- 解决方式是选择特定的事件
e,确保事件e之前的历史被全部节点接收,然后裁剪掉。 - 代价是无法追踪所有的历史因果,只追踪最近发生的因果。
- 解决方式是选择特定的事件
- 稀疏向量: 绝大部分节点彼此互不通信,维护全部向量是极大的浪费,根据系统拓扑来设计向量。
- 系统复杂度降低到实际通信图的复杂度
- Dotted Version Vectors: 讨论Dynamo时再细说。
物理时钟
Lamport
lamport在提出逻辑时钟的论文中指出逻辑时钟排出全序的隐患:可能和用户感知的物理事件顺序不一致。这种情况被称为异常,避免异常有两种途径:
- 把外部事件的顺序信息显式注入系统(逻辑时钟的排序能力只依赖系统内部的消息传递,无法感知外部事件)
- 让系统内部的物理时钟足够精确,使得物理时间本身就能满足更强的时钟条件
举例说明异常:
假设某交易所在上海和深圳分别部署了两套服务集群(容错+低延迟),集群内部使用Lamport时钟排序。收盘时,交易系统整合两个集群的数据进行排序和交易。
- 在某天下午1点,位于上海的笨韭菜闻到了小牛淡淡的香气,害怕被外资抄底,于是下单了某股1000手并成交
- 随后,给位于深圳的老同学呆韭菜打电话,让他也来购入珍贵的国有资产
- 呆韭菜也下单了1000手并成交
现实中,笨韭菜交易成交发生在呆韭菜之前,但是不同集群的时钟独立计数,可能因为笨韭菜成交时上海集群交易频繁从而导致时钟激增到5000,而深圳还是1500;这就导致交易系统收盘排序时,将呆韭菜的订单排到了笨韭菜之前。
为了避免这种情况,必须使用足够精确的物理时钟Strong Clock Condition:
$\text{若 } a \leadsto b \text{(包含外部事件的扩展 happened-before 关系),则 } C(a) < C(b).$
然后引入物理时钟 $C_i(t)$,表示物理时间 $t$ 时进程 $P_i$ 的读数。为保证它们是“真实”的物理时钟,提出两个条件:
- PC1:存在常数 $\kappa \ll 1$,使得对所有 $i$ 有 $|dC_i(t)/dt - 1| < \kappa$。即每个时钟的走时速率接近真实时间。
- PC2:存在足够小的常数 $\varepsilon$,使得对所有 $i, j$ 有 $|C_i(t) - C_j(t)| < \varepsilon$。即时钟之间保持同步。
设 $\mu$ 是任意两个进程间消息的最短传输时间(可由光速与距离估计),则为了防止异常,需要时钟在 $\mu$ 时间内至少前进一点。结合 PC1、PC2,论文得到关键不等式:$\frac{\varepsilon}{1 - \kappa} \le \mu.$
只要该式成立,Strong Clock Condition 就不会被违反。对应到例子,就是只要两地物理时钟的**同步误差(ε)远小于这几秒钟的人类反应时间(μ)**,那么笨韭菜的订单时间戳就一定小于呆韭菜的订单时间戳。
公式的证明由Claude给出,本文不赘述了
论文还给出物理时钟同步算法 IR1′ 与 IR2′:
- $\textbf{IR1.} \quad \text{Each process } P_i \text{ increments } C_i \text{ between any two successive events.}$
- $\textbf{IR2.} \quad \text{(a) If event } a \text{ is the sending of a message } m \text{ by process } P_i, \text{ then } m \text{ contains a timestamp } T_m = C_i(a).$
- $\text{(b) Upon receiving a message } m, \text{ process } P_j \text{ sets } C_j \geq \max(C_j, T_m + \mu).$
论文还证明以下定理:
Theorem. 设强连通通信图的直径为 $d$,所有弧上每 $\tau$ 秒至少发送一条不可预测延迟不超过 $\xi$ 的消息,且 PC1 成立,则在 $t > t_0 + \tau d$ 后 PC2 成立,其中$\varepsilon \approx d(2\kappa\tau + \xi).$
该定理给出了时钟同步误差的上界:$\kappa$ 是单时钟漂移率,$\tau$ 是同步消息间隔,$\xi$ 是网络不可预测抖动,$d$ 是网络直径。
Lamport物理时钟部分是纯粹的学术讨论,最大的价值是证明不依赖中心节点也能让物理时钟同步到任意精度。周期性同步、利用延迟估计调整时钟思想被后来的时间同步算法使用。
TrueTime
Spanner是 Google 的全球分布式数据库,其核心创新是将不确定性主动暴露给应用,让系统主动等待不确定性消失。
与 NTP 返回一个时间点不同,TrueTime 返回一个时间区间 $[\text{earliest}, \text{latest}]$,保证真实时间落在这个区间内。区间半宽记为 $\varepsilon$。TrueTime API 包括:
TT.now():返回当前时间区间。TT.after(t):当 $t$ 确定已经过去时返回true。TT.before(t):当 $t$ 确定尚未到达时返回true。
实现上,每个数据中心部署多个 time master(GPS 或原子钟),每台机器运行 time slave daemon,通过 Marzullo 算法检测和排除异常 master,并将本地时钟同步到非异常 master。生产环境中,$\varepsilon$ 范围约为 1-7 ms,平均值约 4 ms。Spanner 利用 TrueTime 实现外部一致性:若事务 $T_1$ 在 $T_2$ 开始前提交,则 $T_1$ 的提交时间戳小于 $T_2$ 的提交时间戳。具体通过两条规则保证:
- Start:协调者将提交时间戳 $s$ 设为不早于
TT.now().latest。 - Commit Wait:在 $s$ 被确认之前,必须等待
TT.after(s)为真。Commit wait的延迟约为 $2\varepsilon$,通常约 8 ms,最坏情况下可达约 14 ms。
混合时钟
理论上推荐一切从系统内部的可观测性出发,使用逻辑时间;工程实践中则大量依赖物理时间,但默认其只能尽力而为。
- 使用逻辑时钟矛盾的地方在于实际业务和需求往往是和
wall clock相关的,如查询过去5分钟的订单,审计某天的现金流。并且逻辑时钟假设所有信息交换都发生在当前系统内部,这在当今由多个松散耦合子系统构成的环境中已经过时。 - 直接使用物理时钟不能保证因果序(闰秒,虚拟机迁移,POSIX时间非单调更新还会导致回拨);
TrueTime很好,但是太贵了,除了Google这样巨型体量的公司外,很难用得起。而且等过时钟的不确定区间对于写入性能影响较大。
混合时钟应运而生,目标是同时获得逻辑时钟的因果推理能力与物理时钟的 wall-clock 近似能力,并避免TrueTime的阻塞开销和专用硬件开销。
系统建模
混合时钟HLC是一个二元组 $(pt,l)$, 其中pt表示物理时间戳, l表示这个物理时间戳对应的逻辑计数器。
使用l这一计数器是因为虽然时间可以无限划分,但是人类的物理计数器是有精度的,物理计数器走表的速度远小于现代CPU的处理速度,因此多次读取物理时间可能对应一个时间戳,需要一个更快的计数器来表示物理时间戳对应的Epoch。
比较规则是元组的字典序比较,先比较pt,pt相等则比较l(跟Lamport逻辑时钟建立全序的方式一致,引入第二个值来打破平局)。
时钟的更新发生在时间的发生与接收(使用伪代码表示):
- 发生本地事件:
1 | # 发送消息时使用本函数的结果 |
- 收到消息(带时间戳
(pt_m,l_m)): 对齐到已知最大的物理时间戳,然后重置或增加逻辑时间戳
1 | def update_on_receive(self, pt_m, l_m): |
作者将 HLC 设计目标形式化为四条要求。设每个事件 e 被赋予时间戳 l.e,则必须满足:
- 因果保持:$e \mathrel{\text{hb}} f \Rightarrow l.e < l.f$;
- 常数级空间:$l.e$ 由 $O(1)$ 个整数构成,且更新仅需 $O(1)$ 操作;
- 有界表示:$l.e$ 的编码空间有限,实践中希望与 NTP 的 64 位时间戳同宽;
- 贴近物理时间:$|l.e - \text{pt}.e|$ 有界。
- 由于物理时间戳
pt和逻辑时间戳l都是单调递增的,因此可以用于判断happened before关系; - 实践中通常使用64位整型来表示
(pt,l),用高48位表示pt,低16位表示l。能提供微秒级的时间精度,实际使用足够了。 - 节点之间的物理时钟偏差要在一定阈值内,如果超过阈值,那么停止对偏差节点的服务
典型场景
数据库事务时间戳排序
CockroachDB:每个事务开始时,从协调节点的 HLC 取一个时间戳,作为该事务的”读时间戳”。这个时间戳同时承担两个角色:
- 决定事务能读到哪个版本的数据(类似 MVCC 的快照隔离时间点)
- 决定多个事务之间的提交顺序
因为 HLC 保证因果正确性,所以只要两个事务之间存在因果依赖(比如事务 B 是在收到事务 A 的提交确认之后才发起的),HLC 自动保证 HLC(A) < HLC(B),事务排序天然正确,不需要额外协调。
跨节点的因果一致性读取
MongoDB: 写入发生在节点A,读取发生在节点B,如果B尚未同步到数据,能够分辨出需要等待,而非返回旧数据。
- 客户端在写完后记下返回的 HLC 时间戳
T_write,下次读请求带上这个时间戳,告诉读节点”请保证你看到的数据,逻辑时间不早于 T_write”。读节点检查自己同步到的最新 HLC 是否 ≥ T_write,不够就等待或者去主节点读 - MongoDB 内部叫 ClusterTime,本质就是 HLC
参考文献
- 设计数据密集型应用(第二版)
- Distributed systems for fun and profit
- time-clocks.pdf
- Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases